|
||||||
The
Creation Explanation
|
|
 |
Life -- Miracle, Not Accident |
Genes and How They Are Inherited Research since 1953 has revealed much about the structure of chromosomes and genes. A great deal has been learned about the function of the genetic material, in fact, an amazing mass of information about genetics which as yet cannot be fitted into a unified theory of inheritance, embryonic development, speciation, or evolutionary change. Molecular biology is a vast and most complicated field of knowledge which, in the view of believers in creation, affords powerful support for the creation model. We will now devote considerable space to an explanation of this subject to enable the reader to have some appreciation of the exquisite precision involved in the design of molecules and the structures of living things composed of atoms. The following explanation is framed in an outline form and illustrated to aid in understanding the marvelous design of the controlling structures and processes in living cells.7 Replication of DNA: 1. Each chromosome contains one or more molecules of deoxyribonucleic acid (DNA). In order that each daughter cell may have the same genetic information, chromosomes and therefore DNA must be copied when cell division takes place:
2. The DNA molecule is a chain of four kinds of units called nucleotides connected by strong chemical bonds:
3. Because their structures enable them to fit together, like a key in a lock, certain nucleotides have specific mutual attractions, A for T, and G for C. Each of these pairs forms two or three of the type of weak bonds called hydrogen bonds. These bonds correspond to the parts of a key which fit specific parts of a lock. The two members of a pair are said to be complementary nucleotides:
4. DNA occurs in most cells in a two-chained or two-stranded form. The corresponding positions in the two strands are occupied by complementary nucleotides, so the strands attract each other and fit together, held by hydrogen bonds. The two strands twist around each other, so this form of DNA is called a "double helix." A portion of a double helix may be represented by -T-A-T-C-G-G-A-C- -A-T-A-G-C-C-T-G- 5. When DNA is replicated in the cell, the two strands partially unwind under the influence of several protein molecules and separate at an origin where the replication starts. In electron micrographs the separated portion of the double helix DNA looks like a loop or "bubble." The point at each end of the "bubble" where the two separated strands come together and reunite to produce the helical form of the DNA is called a growing fork. At the two growing forks the two separated strands serve as templates on which the complementary strands are constructed. The nucleotides A, T, G, and C are arranged in the proper order by the formation of hydrogen bonds with their complementary nucleotides in the DNA strand (See figure 4-7). The phosphate and deoxyribose portions of the nucleotides are hooked together with strong chemical bonds formed under the control of two DNA polymerase molecules, the a-polymerase and the e-polymerase. These are large protein molecules consisting of chains of about 1,100 amino acid molecules. A polymerase molecule travels along a DNA strand superintending the linking together of the complementary nucleotides to produce a complementary DNA strand. Ten to twenty other protein molecules are also involved in replication, working together in a complex called a replisome. When DNA replication is completed, there are two complete sets of DNA double helices for the two cells which result from the cell division. As can be seen from this much simplified explanation, the DNA replication system is very complicated. It is still far from being fully understood. One unanswered question is how one and only one new copy of each strand of DNA is made when cell division takes place. Much more detailed information about the replication mechanisms will be required to answer this very important question. At a growing fork the replisome adds nucleotides to each new strand at a rate of 100 to 150 nucleotides per second in eukaryotic cells. In bacterial cells the rate is about 1600 nucleotides per second. The probability of error at a particular nucleotide position is estimated to be as low as one in 100 million or one in a billion. The achievement of this accuracy at such high rates is truly amazing. An average gene is duplicated in from one-half second to four seconds. The high accuracy of DNA replication is only possible because the DNA polymerase molecule also proof reads the new strands. When an error is detected a correction mechanism is activated to replace incorrect nucleotides with the correct ones. If the proofreading and repair mechanisms were missing from the replication process, the resulting copies of DNA would be so loaded with destructive errors that cell division would be stopped after a very few cell divisions. This would lead quickly to the extinction of the population. This raises a difficult question for the abiogenesis researchers and theorists. The original protocells which they believe arose spontaneously in some primeval chemical pond would be very simple. Therefore, they could not have developed the proofreading and repair mechanisms until later. Consequently, their initial DNA replication would have been so inaccurate that the newly arrived living cells would have been able to continue cell division only a very few times before the resulting new generation of cells could not survive. Thus the protocells would become extinct before they had a chance to evolve to higher complexity.8
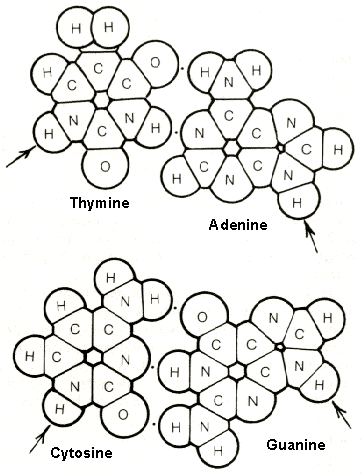
figure 4-5. The nitrogen bases which are combined with phosphoric acid and deoxyribose to form the nucleotides are planar molecules. Show here is the lock-and-key fit of the two pairs, thymine-adenine and cytosine-guanine, held together by the weak force of hydrogen bonds (represented by single dots). A hydrogen bond can be formed between a nitrogen and an oxygen atom, between two oxygen atoms, or between two nitrogen atoms, by mean of a hydrogen atom which is attached by a strong bond to one of the two atoms. Note that thymine and adenine each have two hydrogen bonding sites which can fit together, whereas cytosine and guanine each have three sites which are differently arranged in space. Therefore, the thymine "key" can fit only the adenine "lock," while the cytosine "key" can fit only the guanine "lock." The arrows indicate the [point at which each nitrogen base attaches to deoxyribose in the DNA strand.
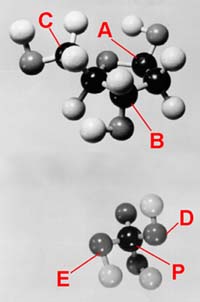
figure 4-6. The deoxyribose (top) and phosphoric acid (bottom) molecules are not planar but three-dimensional. Thus they are represented here by means of ball models so that the structures can be visualized. The angles in space formed by the bonds from the deoxyribose molecule and from the phosphorus atom (P) are such that, with proper rotation of the bonds, a spiral or helical backbone for the DNA strand is formed. The twist and diameter of the spiral is just right to hold the A-T and C-G hydrogen-bonded pairs like a stack of flat pancakes up the center of the two-stranded DNA double helix. A nitrogen base (A, T, C or G) attaches to the deoxyribose carbon atom at A. The deoxyribose attaches to two phosphate group (PO4) oxygen atoms at B and C. The connections of two deoxyribose molecules to the phosphate are at D and E. 6. The nucleotides are brought into the DNA synthesis process in the form of energy-rich triphosphate compounds. The formation of each of these involves a dozen or so chemical steps, each one catalyzed by a different specific enzyme molecule made up of a chain or chains of hundreds of amino acid molecules.
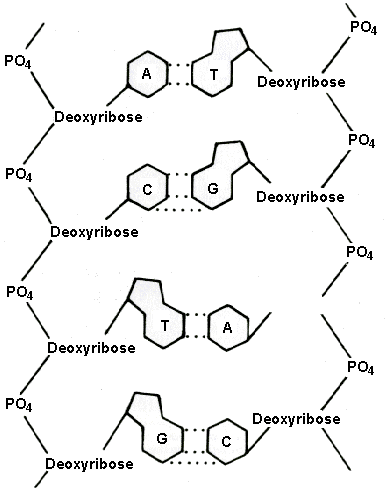
figure 4-7. The phosphate-deoxyribose backbones of two DNA strands hold their attached nitrogen bases in proper position so that complementary bases A and T or C and G on opposite strands can form hydrogen-bonded pairs. The coded information in a gene is contained in the sequence of the nucleotides which act as letters in a four-letter alphabet. Each phosphate-deoxyribose-nitrogen base unit is called a nucleotide.
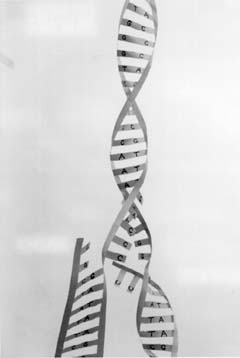
figure 4-8. A model showing the actual shape of the DNA double helix as presently understood.
figure 4-9. When the two-stranded DNA helix is replicated prior to cell division, the two DNA strands partially unwind and separate in a process controlled by special enzymes. The two old strands serve as templates on which the new strands are formed. This very abbreviated description of the process by which DNA molecules containing the portions called genes are copied introduces us to the fantastic complexity of structures and activities in the cell connected with inheritance. Genes correspond with Mendel's "factors" which control particular inherited traits passed from generation to generation. It should be pointed out, however, that DNA does not carry all inherited information. Certain crucially important pattern information independent of DNA is carried in the structure of the cell membrane or cortex (Latin cortex, "bark") and very likely also in the structure of the cytoplasm (the internal contents of the cell other than the nucleus containing the chromosomes with their genes). The existence of this cortical inheritance information as it has been called, has been established in experimental studies with protozoa, amphibia, cephalopods, desmid algae, and flowering plants.9 Essentially all evolutionary speculations and research concerning mechanisms for evolutionary change are centered in the structures and activities of the chromosomes and their DNA molecules which contain the genes. British trained geneticist A.J. Jones, a creationist, has proposed that the cortical inheritance may be very important. He suggests that perhaps the separateness and uniqueness of the created kinds is determined by cortical inheritance.10 Robert Kofahl has offered an even more radical proposal, namely, that the uniqueness and separateness of the created kinds is determined by supernatural providential control over all living things. The basis for this concept is the fact that the DNA of, for example, the human species, may have information storage capacity that is insufficient by a factor of 1/7000 to 1/140,000 to define and direct the production of the neuronal network of the cortex of the human brain.11 And this does not take into account the information required for all the rest of the structures and functions of the human body. This proposal, which is explained in Appendix E, has been vigorously criticized by a university professor emeritus of biology, Dr.Richard D. Lumsden, who is now active in the creation ranks.12
References 7. Watson, James D., Molecular Biology of the Gene, 2nd Edition (W.A. Benjamin, New York, 1970); Alberts, Bruce, et al., Molecular Biology of the Cell (Garland Publishing, New York, 1983); Darnell, James, et al., Molecular Cell Biology (W.H. Freeman, New York, 1986; Stryer, Lubert, Biochemistry (W.H. Freeman, San Francisco, 1975), pp. 555-707. 8. Lambert, Grant R., J. Theoretical Biology, Vol. 107, 1984, pp. 387-403. 9. Sonneborn, T.M., Proc. of the Royal Soc., Vol. B.176, pp. 347-366(1970); Jones, A.J., Creation Research Soc. Quarterly, Vol. 19, 1982, p. 15. 10. Jones, A.J., ibid., pp. 13-18. 11. Kofahl, Robert E., "Is the Genome Sufficient, Where Is the Design Information, and What Limits Variation?" Creation Research Soc. Quarterly, Vol. 28, March 1992, pp. 146-148. 12. Lumsden, Richard D. and Gaynell M. Lumsden, "Alleged Informational Insufficiency of the Genome: A Rebuttal," ibid., Vol. 29, Sept. 1992, pp. 102-104. |
|
|
|