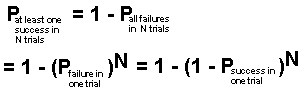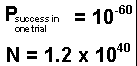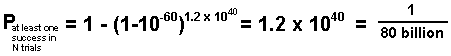|
||||||
The
Creation Explanation
|
|
 |
Life -- Miracle, Not Accident |
Proteins by Chance -- Faith in the Impossible It was indicated earlier that the formation of long polymer chains corresponding to proteins, DNA and RNA in living cells is an extremely difficult problem. As chemists know from frustrating experience, the most probable product to be expected from all of the potential reactions in the hypothetical complex organic "soup" would be a "black, intractable tar." The early schemes pictured an ocean filled with a dilute solution of amino acids which would react for a sufficiently long time to link up to form long chains when the chemical reactions reached the equilibrium point. But about half a kilocalorie of free energy must be added to make each link in a protein chain. For a protein chain with 100 links this would be about 50 kilocalories. From this it can be calculated that, when the reactions had all come to equilibrium so that no more products were being formed, the concentration of a particular protein chain of 100 amino acid residues would be so dilute that there would be only one such molecule in a volume of the reaction mixture equal to 10200 earth oceans! The reason for this small concentration of any protein chain in the assumed organic soup is that the reaction to add amino acid residues to a chain is a reversible reaction in the presence of water. This means that the chemical bonds between the links in the chain are being broken as well as made. Since the amount of chemical energy available to make the bonds in a chain is very small compared with the 50 kilocalories required to make all the bonds in a 100-unit chain, only an extremely small concentration of the 100-link protein chains can exist in the mixture when chemical equilibrium has been reached. In fact, the calculated concentration is so low as effectively to equal zero. As a result it was necessary to seek some non-equilibrium situation which uses activated molecules which contain the energy needed to form the desired product molecules. One research project started with chemically activating an amino acid by combining it with adenylic acid to form an aminoacyl adenylate. This product when shaken in aqueous solution with Montmorillionite clay adsorbs on the clay particles and polymerizes to form chains continuing up to 56 amino acid residues.40 This result is the closest approach thus far to spontaneous production of protein-like molecules in aqueous solution. It was thought to hold some hope that a simple enzyme molecule of, say, 100 amino acid residues could form spontaneously. But there are serious problems with this idea. The first problem is that there is as yet no known plausible way in which the energy-rich aminoacyl molecules, the necessary activated building blocks, could form spontaneously in the ancient oceans. Another problem is one of statistical probability. Let us assume that a set of conditions is found under which a mixture of amino acids chains (called peptide chains) containing 100 amino acid residues can form. To get the life process started, it would be necessary to produce such a chain that would be a protein with the properties of an enzyme to, for example, catalyze the copying of itself according to the information coded in a DNA or RNA molecule. Using the twenty commonly occurring amino acids, any one of the twenty kinds can be placed by chance in each of the 100 places in the chain molecule. Therefore, the total number of different 100-unit molecules which can be constructed is equal to 20 multiplied by itself 100 times, or 20100 = 10130. this is the number "1" followed by 130 zeros. Let us explain this probability by using a hypothetical protein chain just three units long. Assume also that there are just two different amino acids making up the chain. A and B, which can be put in the three position in the chain. Then the possible different chains would be A-A-A, B-A-A, A-B-A, A-A-B, B-B-A, B-A-B, A-B-B- and B-B-B. This is a total of eight different amino acid sequences reading from left to right. This number can be calculated by multiplying the numbers of different amino acids that can occupy the three positions in the chain. That is, N = 2x2x2 = 23 = 8. This is why we said that for a 100-unit chain constructed from 20 different amino acids the possible number of different chains would be 20100, which is equal to 10130. Now it is known that in an enzyme molecule which performs a specific function, a certain amount of variability is allowable in the amino acid sequence without destroying the enzyme activity of the molecule. Cytochrome c is an important enzyme for the production of energy in cells. This enzyme has been extracted from about 100 different species of plants and animals, and the sequence of the 20 amino acids has been deciphered for the enzyme from each of these species. From this information it is seen that the average variability in the 100 different positions along the chain is about 2.7 different amino acids. However, 35 of the 104 positions in the amino acid chain are invariant in the different species (See Chapter-7). Let us make a generous assumption that in our hypothetical evolving enzyme molecule, an average of five different amino acids may fit into each position in our hypothetical 100-unit amino acid chain. Then the total number of different chains that could be produced having the desired enzyme function would be 5100 = 1070. We may now calculate the probability that for any new 100-unit protein molecule constructed at random in the primeval amino acid soup, the probability of a workable enzyme molecule would be:
This is a very small probability of success in any one trial construction of a protein chain by chance. But the evolutionary argument is that even with such a small probability, given sufficient time, the number of trials will be so great that success is inevitable. Let us look at that argument. Let us assume that one percent of the earth's atmospheric nitrogen, combined with the required oxygen, hydrogen and carbon, is converted into 100-unit protein molecules. This would be about 95 pounds of protein per square foot of the earth's surface, or a total of about 1.2x1040 protein molecules. Let us repeat this process annually for one billion years, for a total of 1049 trial constructions of a 100-unit protein molecule. The probability of at least one success, i.e., forming a single copy of a particular working enzyme molecule in N trials will be:
Now we substitute in this formula the numerical values
The result is that the probability of forming just a single copy of a working enzyme molecule in one year would be:
This is surely a very small probability. See Appendix-A for the development of these formulas. Now let us visualize what these numbers mean. They mean that to have just one chance in 80 billion of finding at least one accidentally formed active enzyme molecule, one would have to search, molecule by molecule, through 260 trillion tons of fresh protein muck every year for one billion years! But, of course, in our exceedingly oversimplified model for the beginning of life we have assumed that the right protein molecule must get hitched up with a DNA or RNA molecule which codes for the same protein or a similar one with the same capacity for initiating life. So let us assume that, in addition to the 1040 protein molecules there is formed an equal number of DNA molecules in each year's batch of muck. We shall also assume that each molecule experiences 1010 collisions per second with other molecules, or 1010x3x1016 per year. For the 1040 protein molecules there would be 1010x3x1016x1040/2 = 1.5x1066 pair collisions per year. Remembering that the probability that any protein or DNA molecule of the length we are considering is suitable for starting life is only 10-60, we can now calculate the probability of a successful romance (protein molecule meets corresponding DNA molecule). It is:
These mathematical estimates make it clear that even if the necessary DNA and protein molecules could form by chance, they would never find each other in this world, regardless of how old the world is. Hence no romance and no life. Could it be that this explains why most people feel that life without romance is a pretty dead affair? In our probability estimates, the assumptions have all been made so as greatly to favor the successful production of our hypothetical enzyme, DNA and romantic molecule pair. Nevertheless, even under the most favorable imaginable conditions the calculated probability of success is still effectively zero. Thus we see that in the real world time is not the "hero" who can make the impossible chemical origin of life possible. In 1977 H. P. Yockey, an international authority on the application of information theory to biology, published a much more sophisticated analysis of the probability of the spontaneous formation of an enzyme molecule having the information content required to participate in life.41 This was two years after the publication of the first edition of The Creation Explanation(1975). Yockey also used cytochrome c as his model enzyme, making a detailed study of the information content of that enzyme, using the latest published information. He calculated that the cytochrome c molecule carries 215.9 bits of information. From this we can calculate that the probability of spontaneous formation of the molecule in one trial would be P = 2-215.9 = 10-65. Thus his analysis gives a calculated probability smaller than our more rudimentary estimate by a factor of 100,000. Therefore, our elementary analysis has been amply justified and shown to be quite conservative. Since it is clear , then, that complete enzyme molecules and their coded DNA molecules. to which they are coupled by an accurate system of information transfer and translation, could not come into being by chance in a completed form, theoreticians are forced to look for some more rudimentary interactions between the amino acids and the nucleotides which make up, respectively, the protein and DNA or RNA chains. They have tried to discover some simple interactions involving only a very few amino acids and nucleotides which could have started the initial rudimentary coupling between DNA- or RNA-coded specifications for the sequence of amino acids in the original enzymes.
References 40. Paecht-Horowitz, M. et al., Vol. 228 (1970), p. 636. 41. Yockey, Hubert P., Journal of Theoretical Biology, Vol. 67 (1977), pp. 337-398. |
|
|
|